


概要
Power Automate Desktop(以下、PAD)を使うとシンプルな(複雑なデータ加工などが必要ない) Webスクレイピングであれば簡単に行うことができます。 今回は、PADを初めて触る方でもお試しいただけるシンプルな例として、 イースト株式会社(当社)の技術ブログの記事タイトルを抽出してExcelに出力する手順を ご紹介いたします。
事前準備
- Power Automate Desktopをインストールする 下記ページ内のリンクからインストーラーをダウンロードして実行します。 https://learn.microsoft.com/ja-jp/power-automate/desktop-flows/install
- ブラウザにPower Automate Desktop用の拡張機能がインストールする 今回はMicrosoft Edge を使用するためMicrosoft Edge に拡張機能「Microsoft Power Automate」をインストールします。
フローを作成する
Microsoft 365のPowerAppsでアプリを作成します。
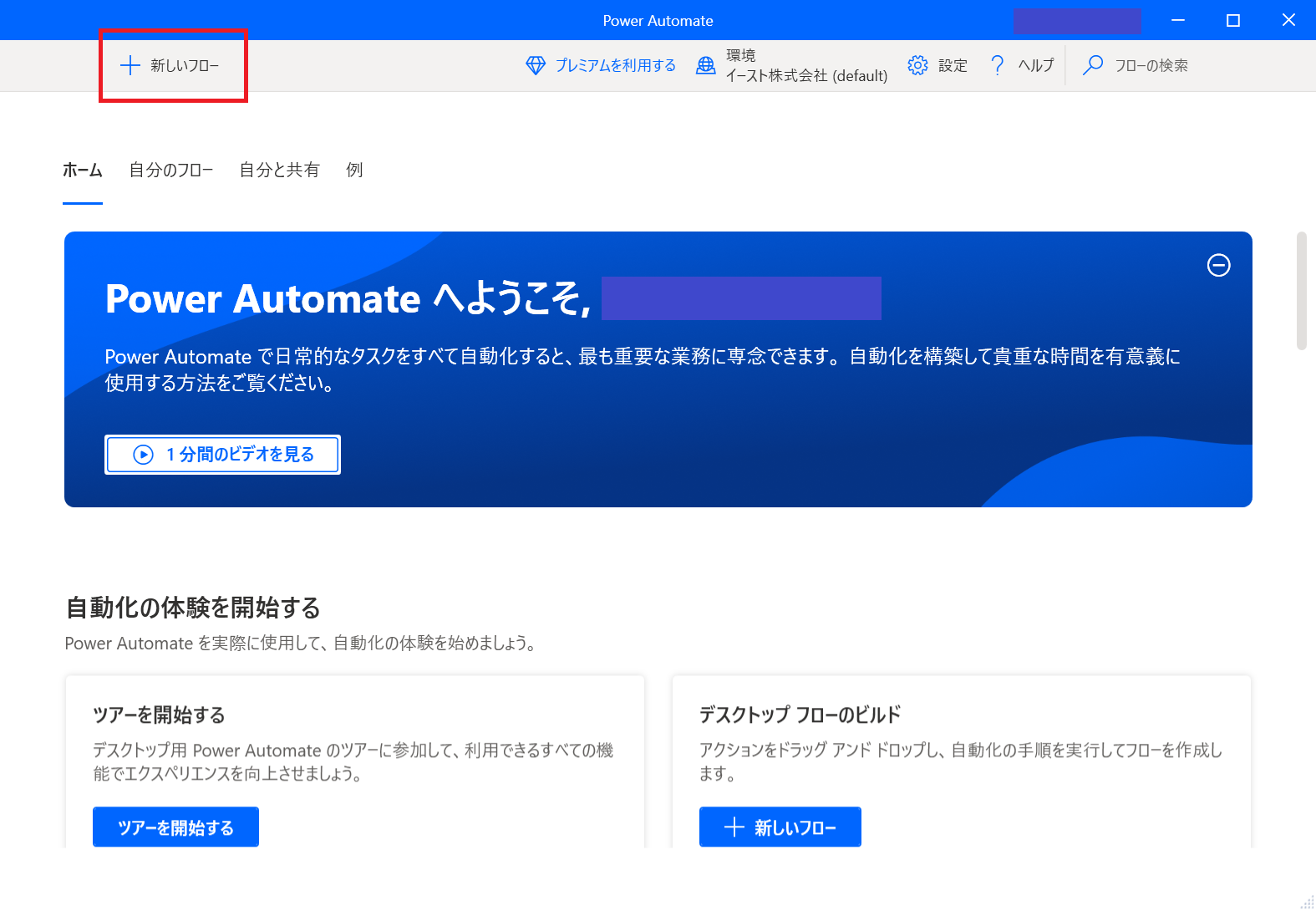
- 新しいフローを追加する 「新しいフロー」をクリックします。
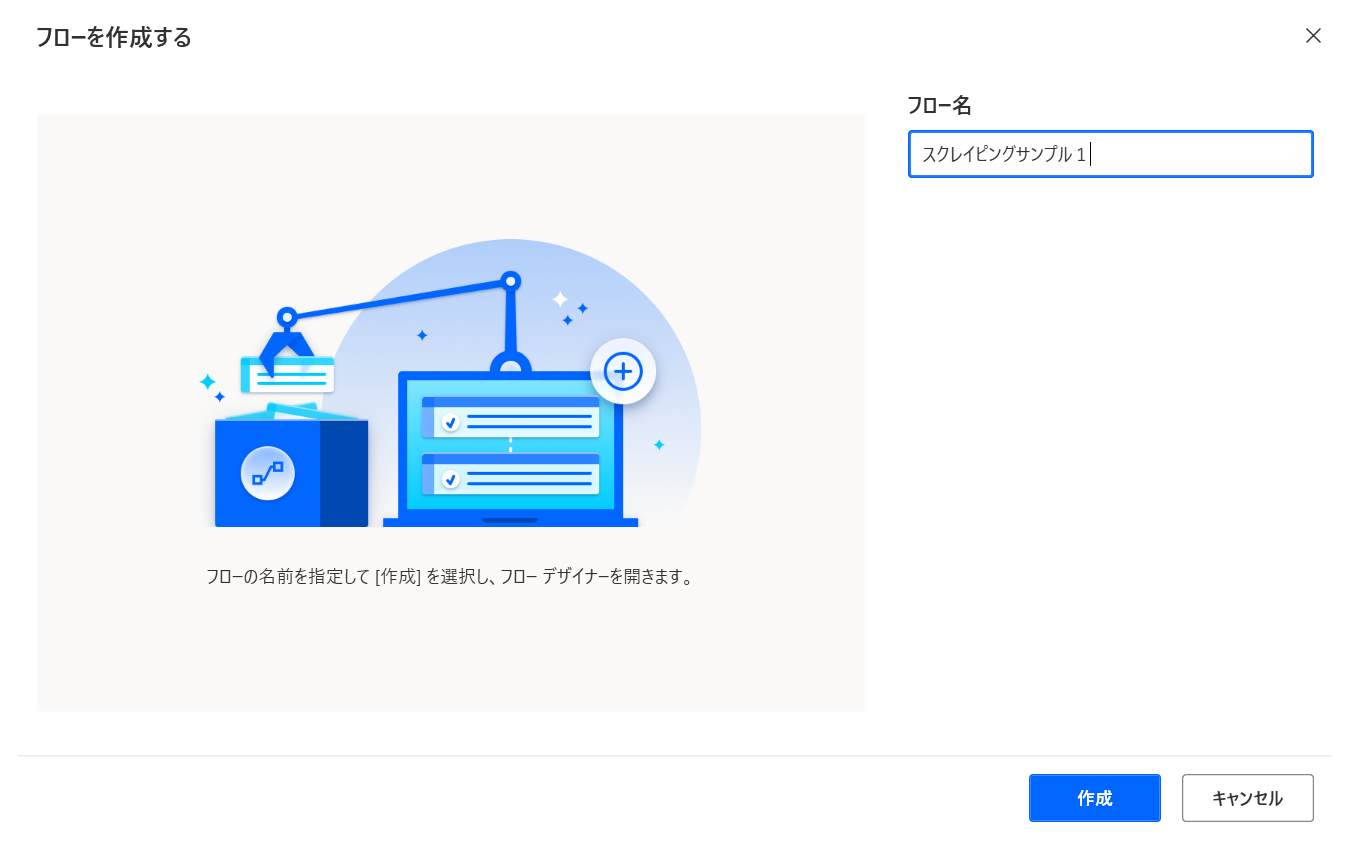
フローを入力します。
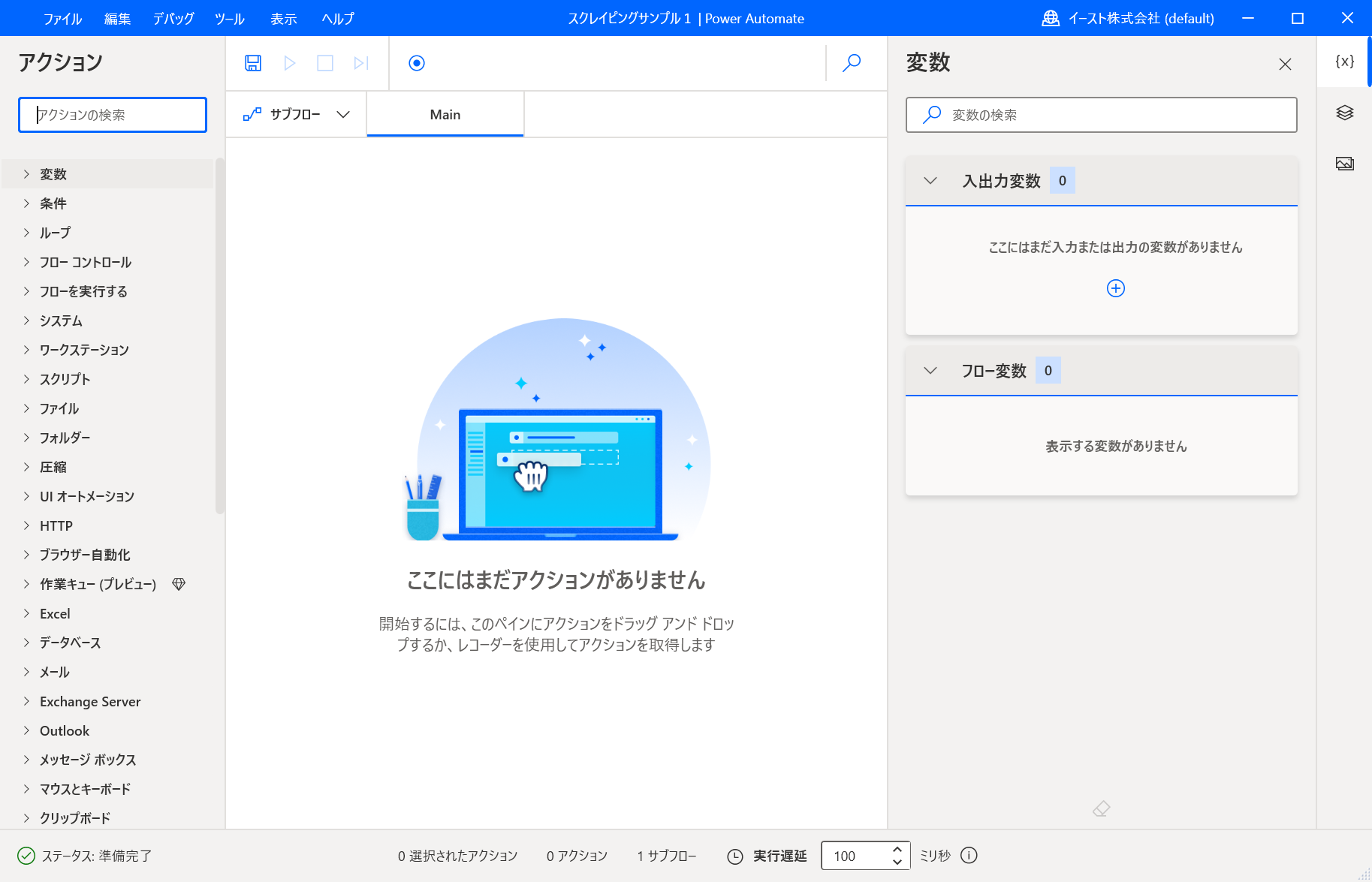
フロー作成画面が表示されます。
- ブラウザーを起動するアクションを追加する 「新しいMicrosoft Edgeを起動する」をドラッグアンドドロップして フローに追加します。
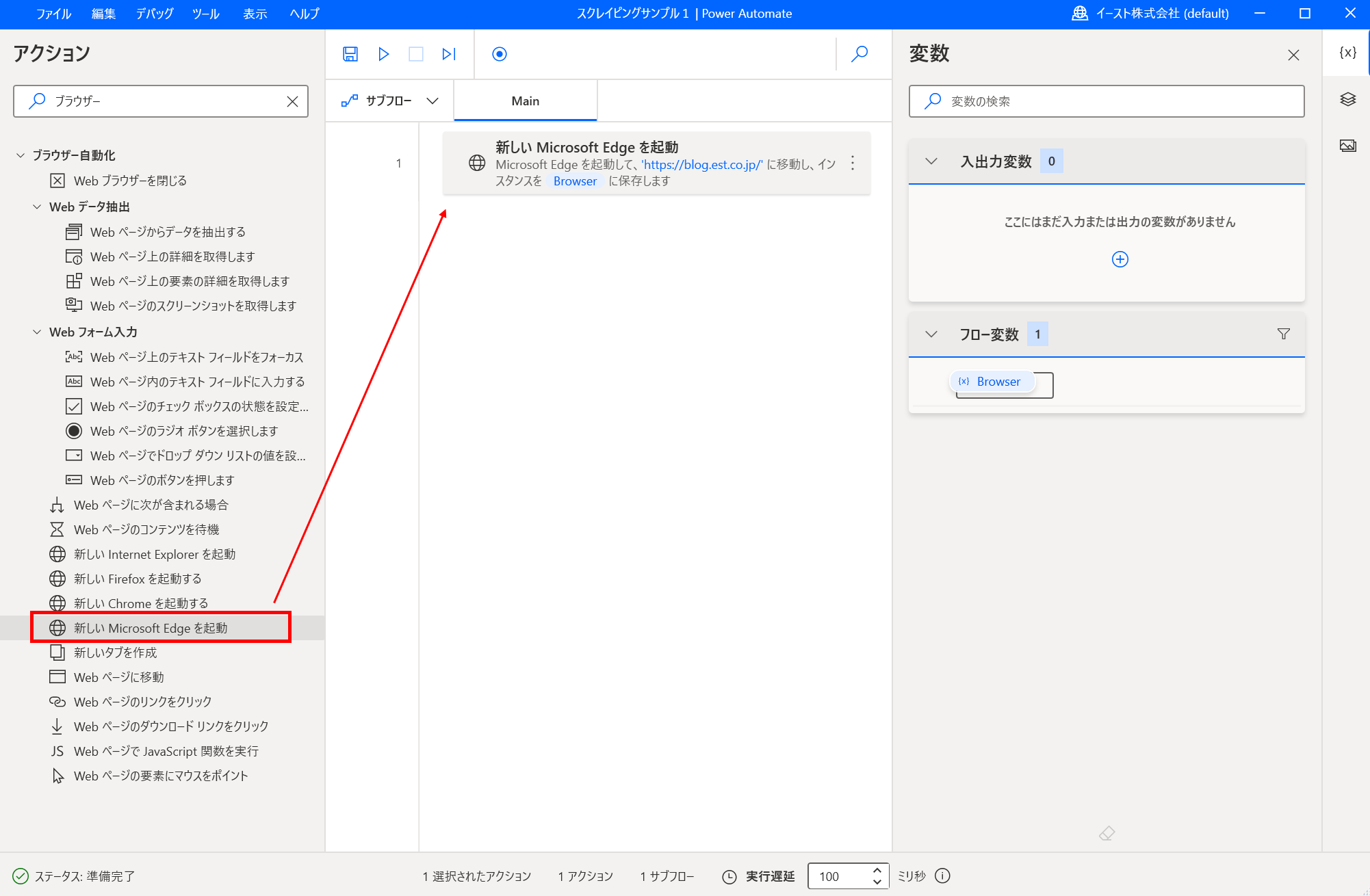
パラメーターの入力画面が表示されます。 初期URLにイーストの技術ブログのURL https://blog.est.co.jp/ を入力して「保存」ボタンで保存します。
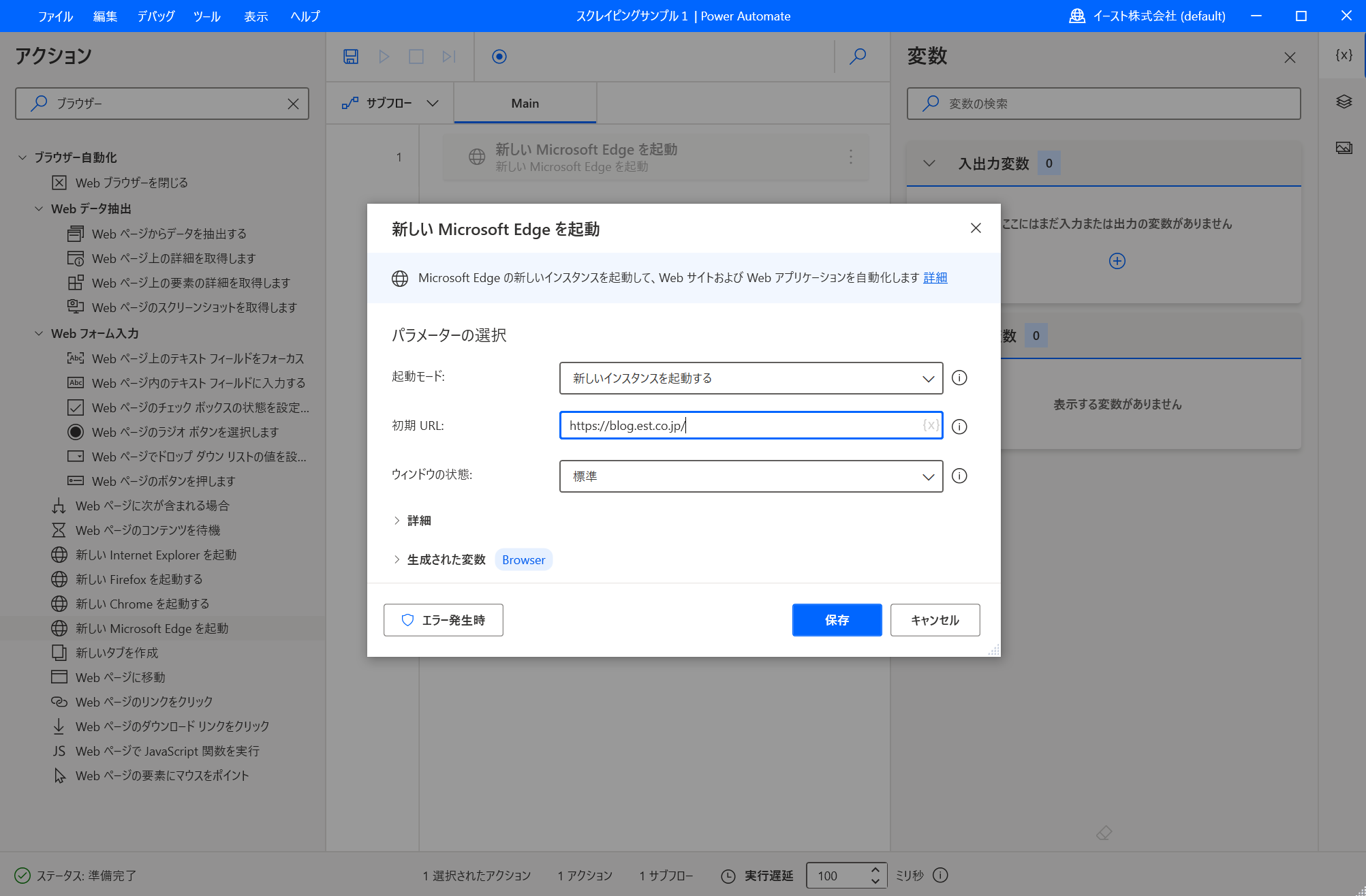
- Webページからデータを抽出するアクションを追加する 「Webページからデータを抽出する」をドラッグアンドドロップしてフローに追加します。
パラメーターの入力画面が表示されます。 ここでパラメーターの値は初期値のまま、入力画面を閉じないでそのままにしておきます。
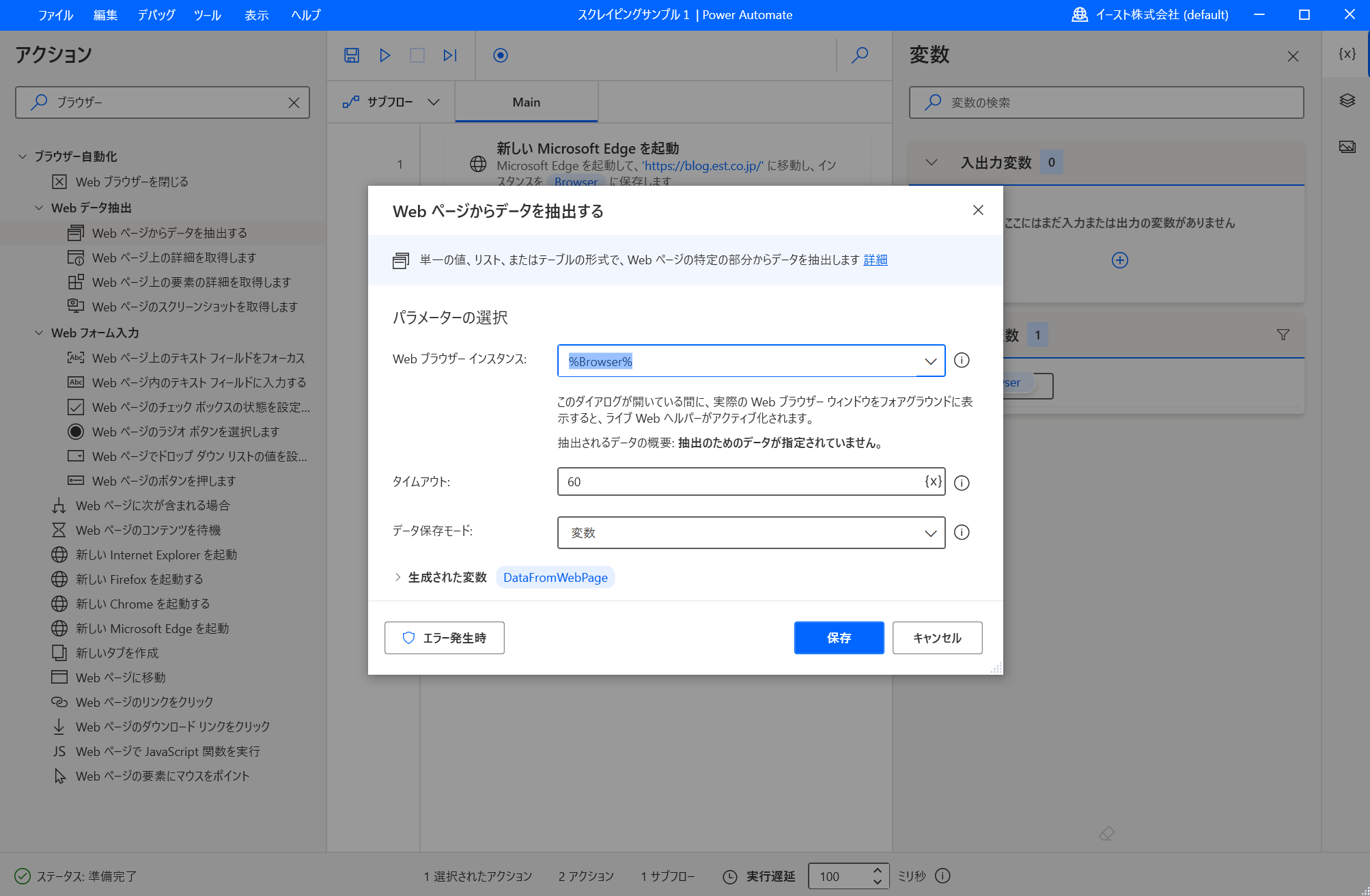
PADの「Webページからデータを抽出する」アクションのパラメーター入力画面を表示したまま、Microsoft Edge を起動してイーストの技術ブログを開きます。 Microsoft Edgeを起動して少し待つと「ライブWebヘルパー」の画面が表示されます。
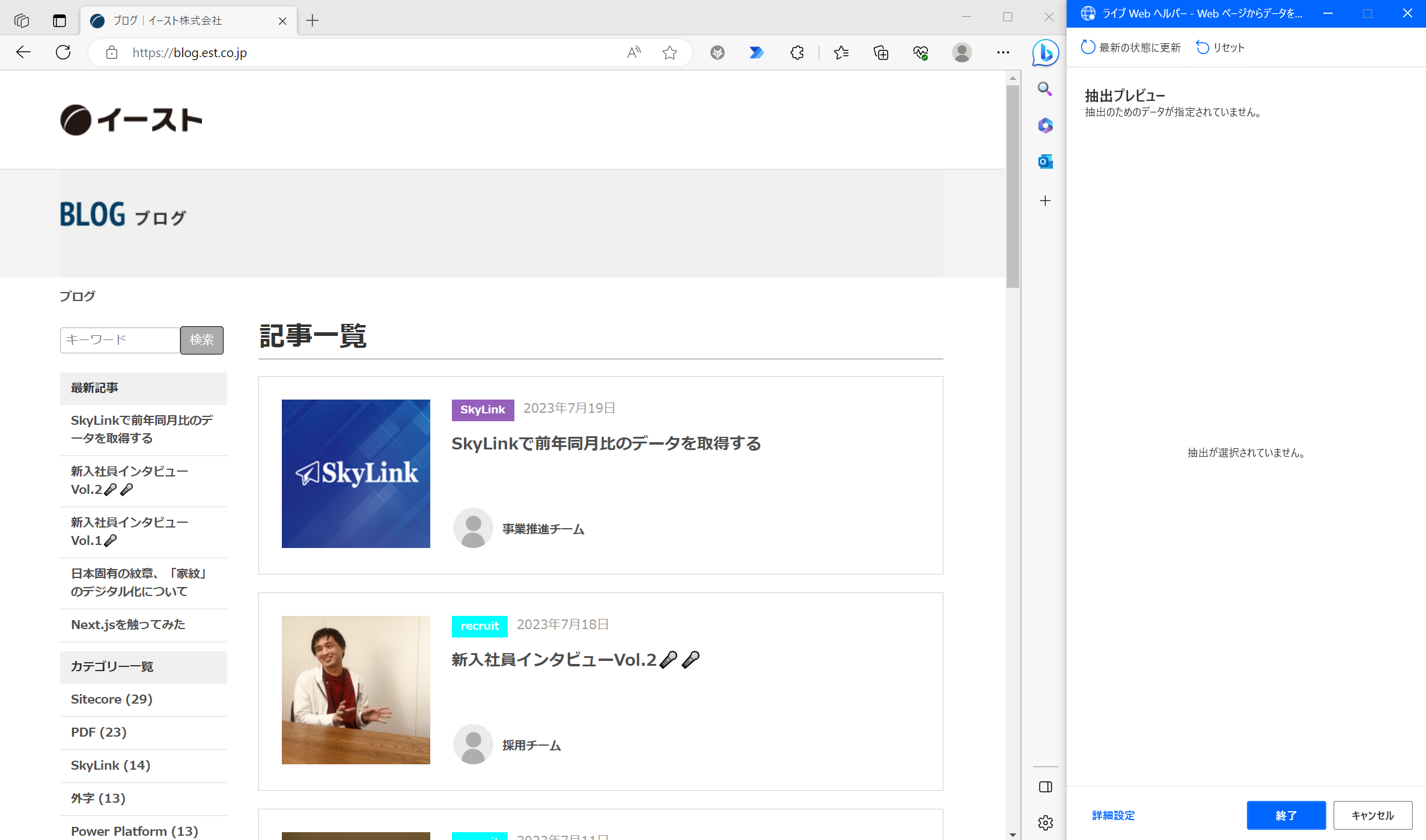
「ライブWebヘルパー」が表示された後、ブラウザ上でマウスカーソルを移動すると赤い枠が表示されるようになります。 赤枠でブログの記事タイトルを選択した状態で右クリックして「要素の値を抽出」-「テキスト」をクリックします。
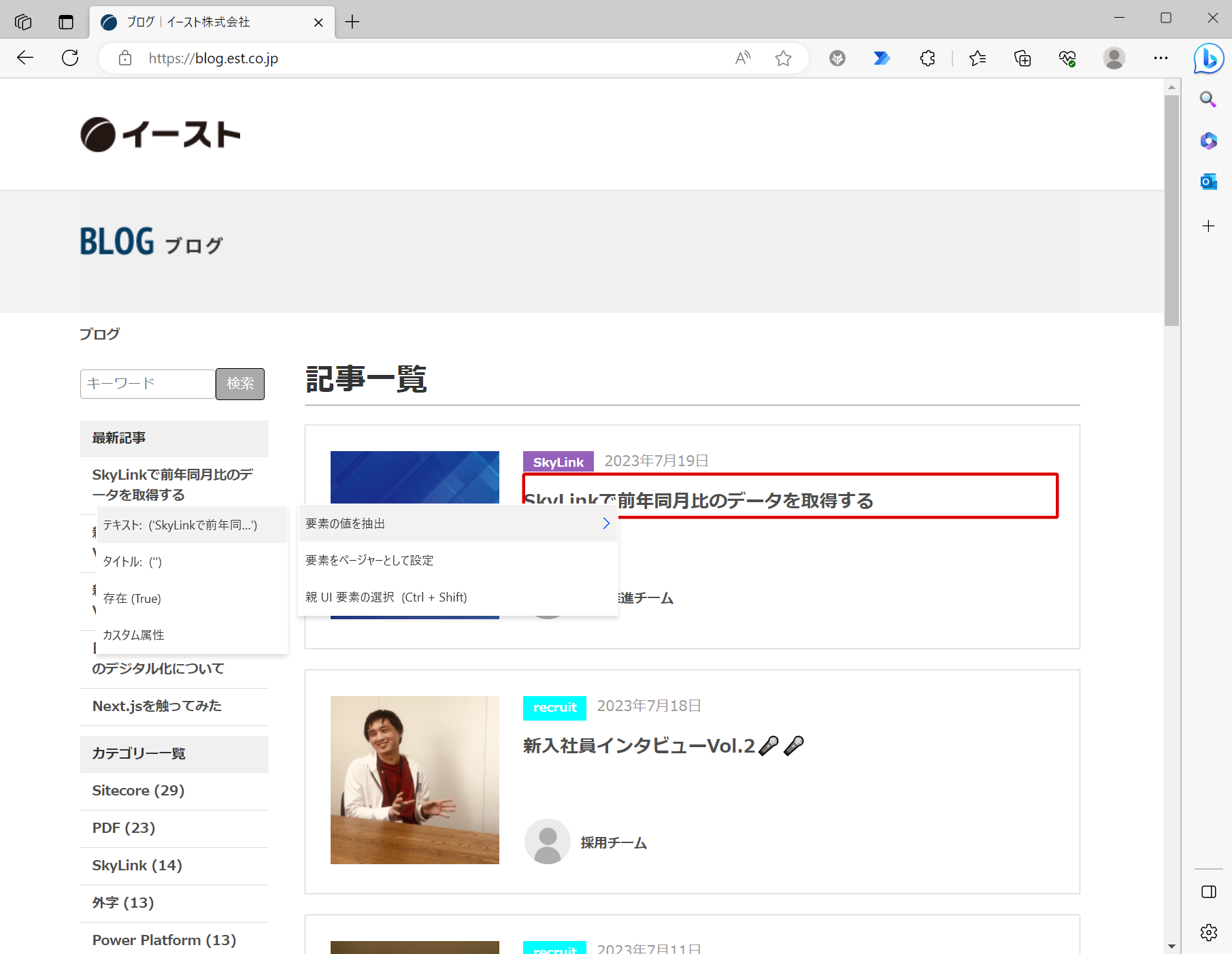
「ライブWebヘルパー」にデータ抽出した値のプレビューが表示されます。
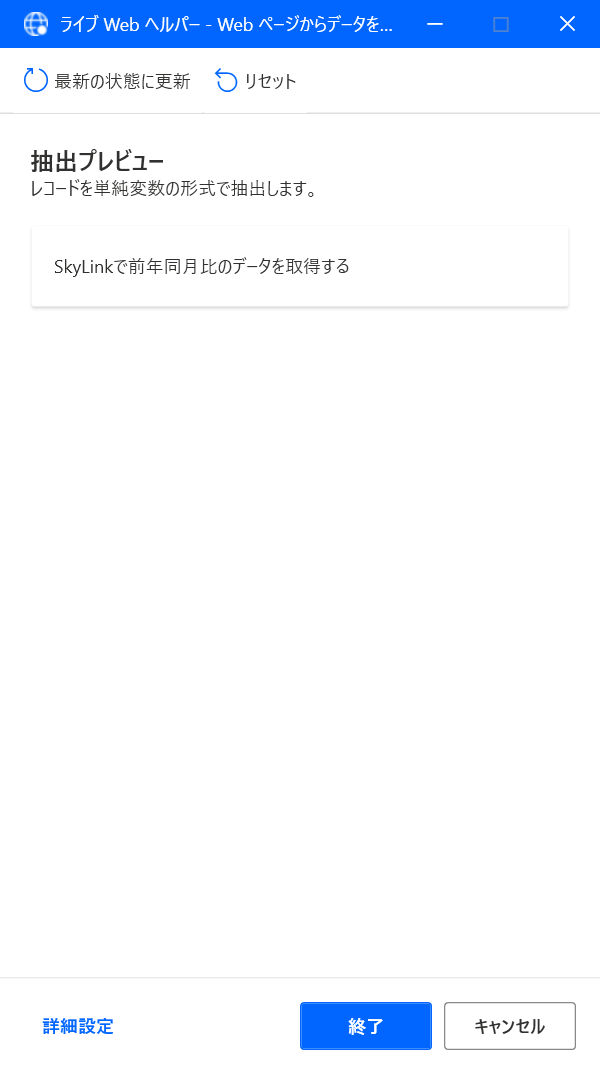
同様に次の記事のタイトルを抽出対象に設定します。
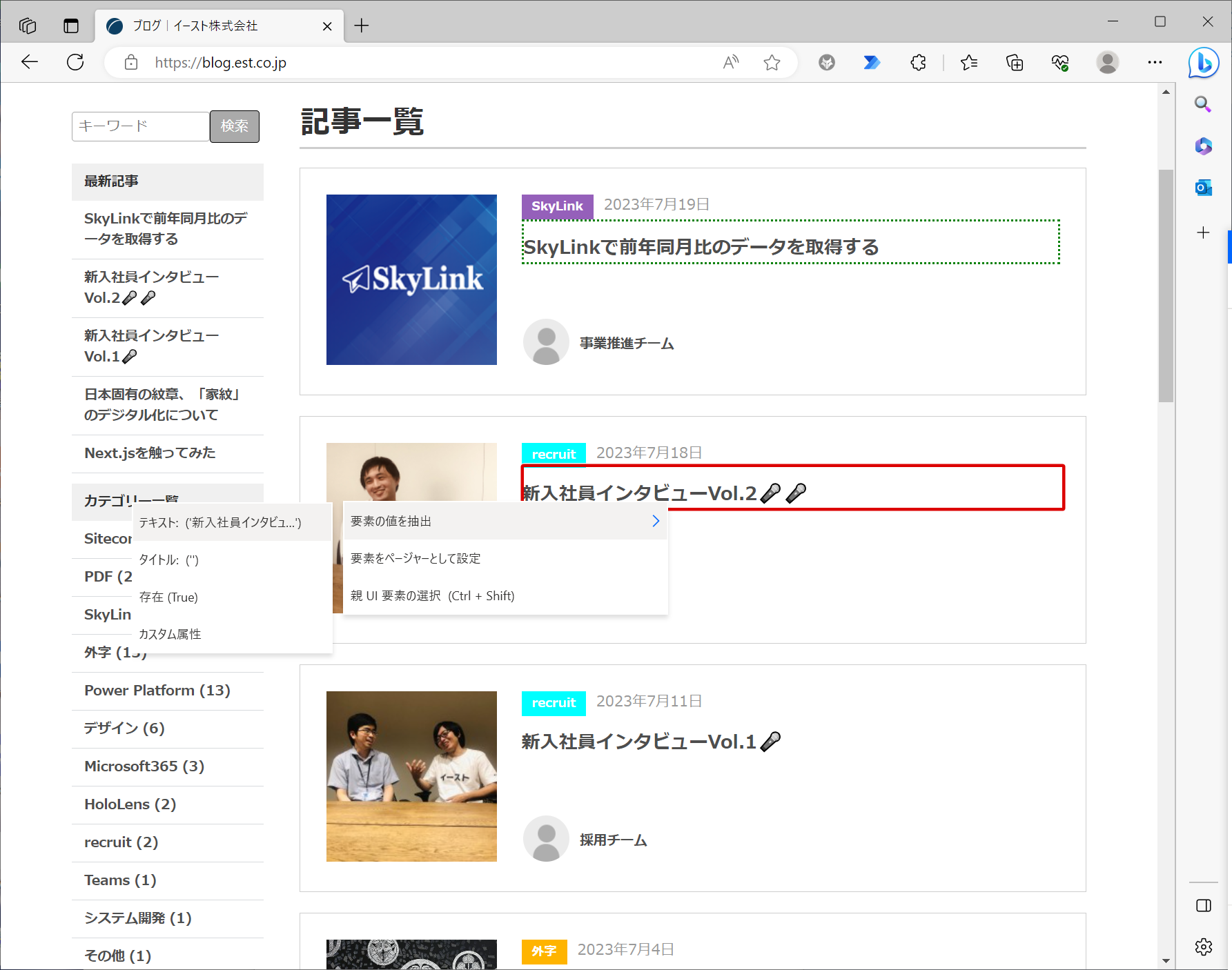
2つめの記事タイトルまで抽出対象に設定すると3つめ以降の記事タイトルも抽出対象になります。 ※PADが自動で3つ目以降も抽出対象にしてくれます。 「ライブWebヘルパー」の抽出プレビューを見ると1ページ内の5件の記事のタイトルが抽出対象になっていることがわかります。

このままだと1ページ目の5件しかデータ抽出されないので、2ページ目以降もデータ抽出できるように設定を行います。 次ページへのリンクに赤枠を当てた状態で右クリック → 「要素をページャーとして設定」をクリックします。
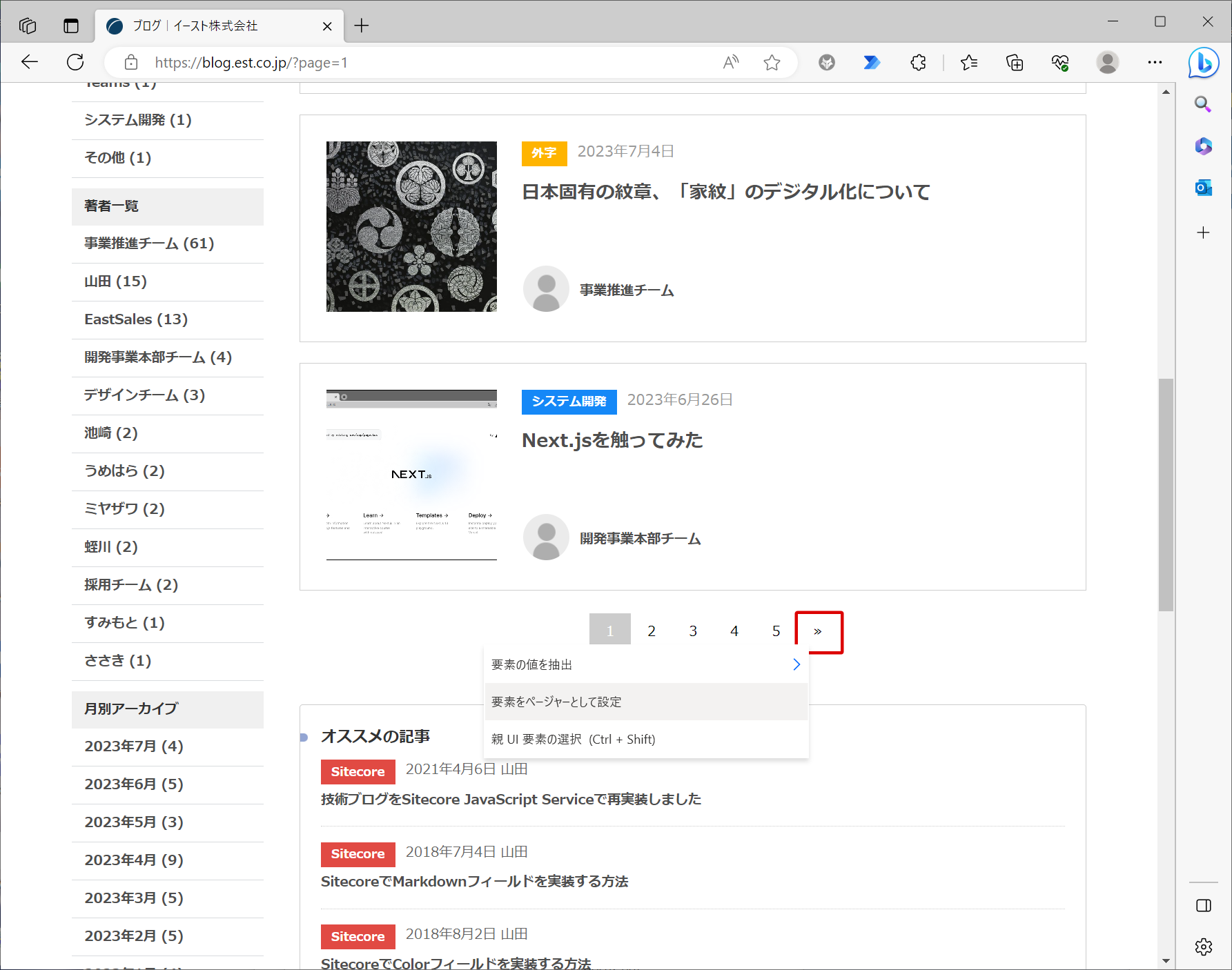
「ライブWebヘルパー」に「次のページの対応する値...」が追加されます。

これでページングに対応した設定ができました。 「終了」をクリックして「ライブWebヘルパー」を閉じます。 「処理するWebページの最大数」で何ページ目までデータ抽出の対象とするかを設定します。 ここでは5ページ目までを抽出対象としています。
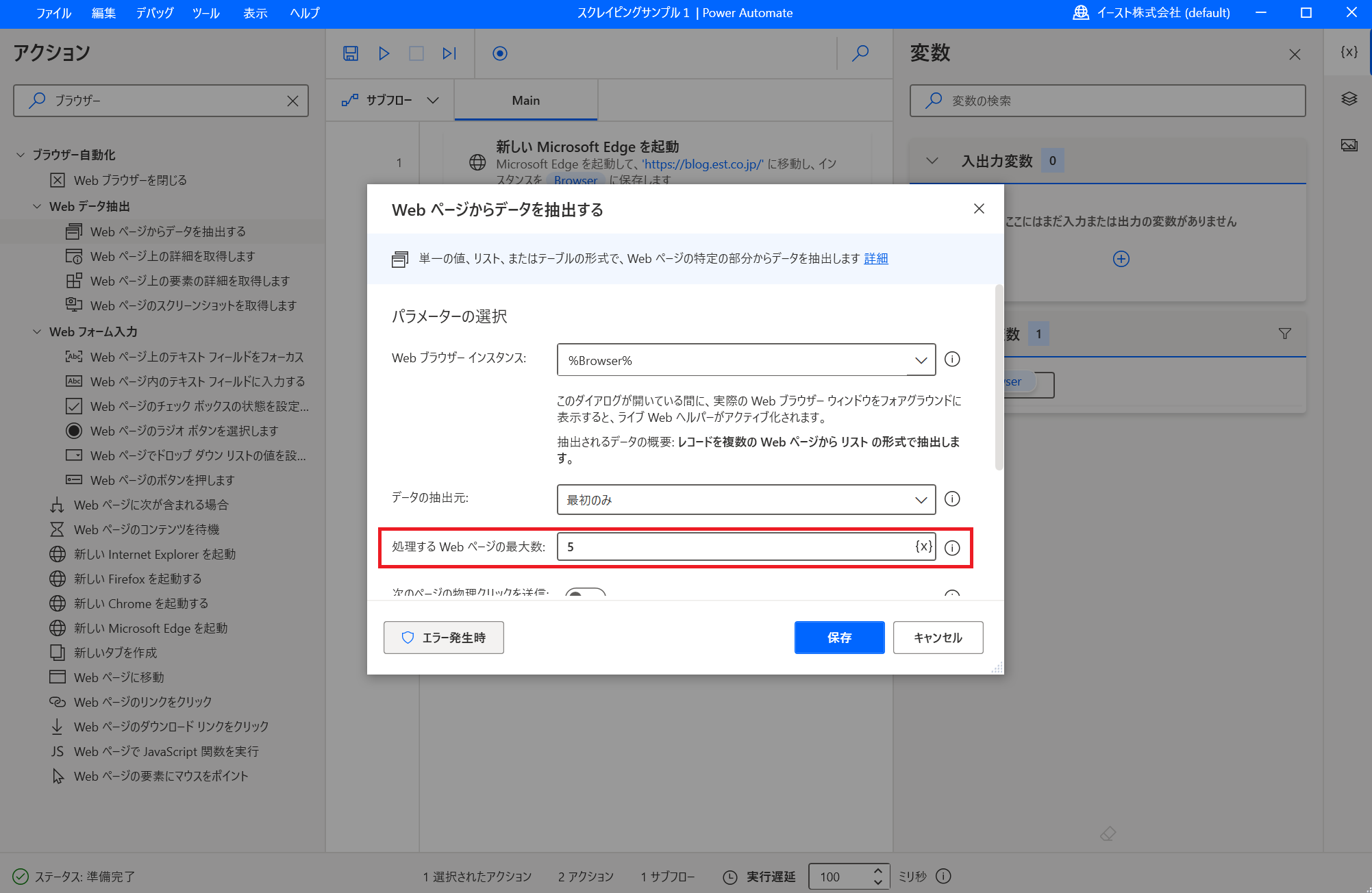
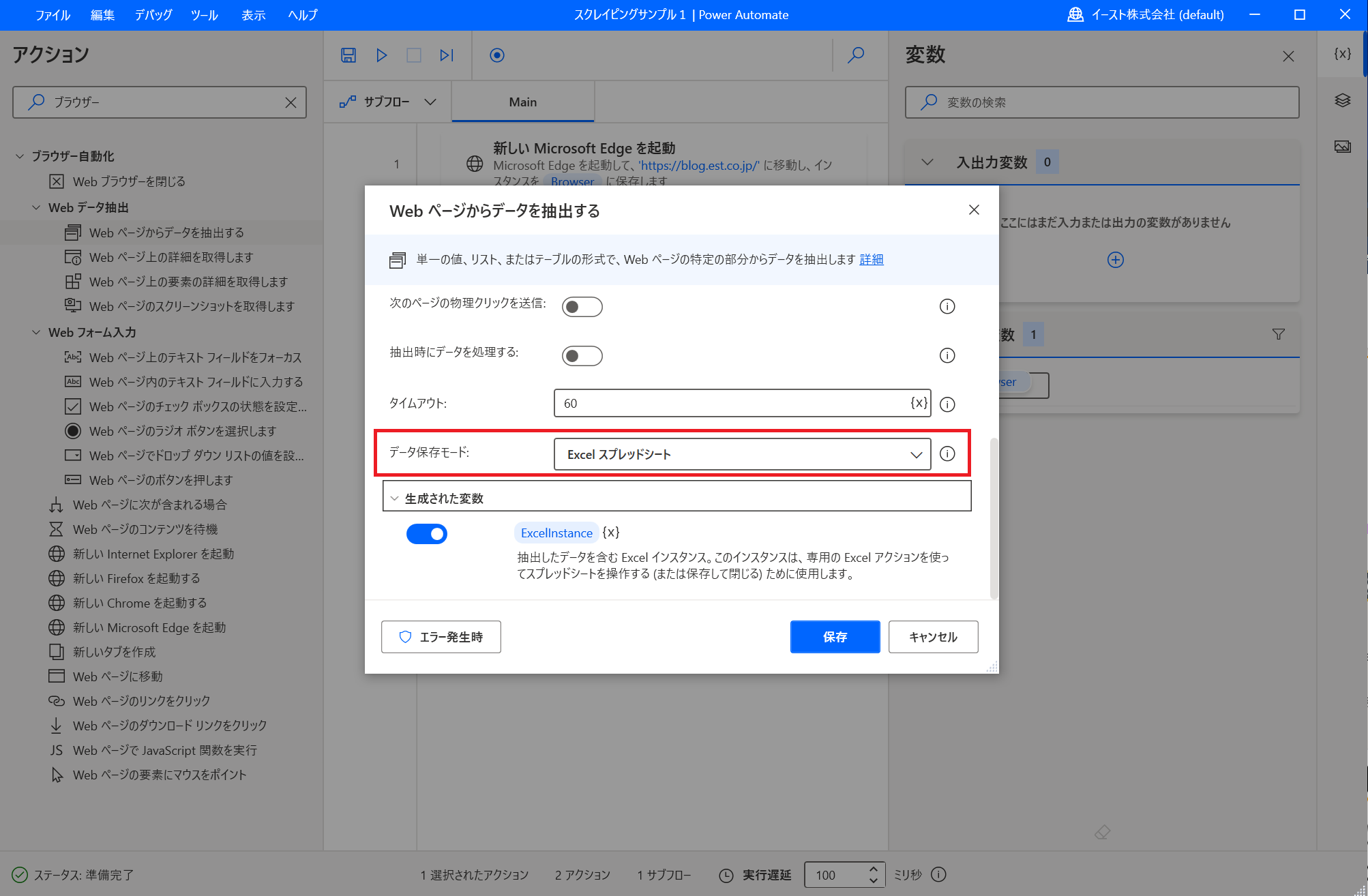
もし、全ページを抽出対象とした場合は「データの抽出元」ドロップダウンで「すべて使用できます」を選択します。 抽出したデータをExcelに出力するように変更します。 「Webページからデータを抽出する」ポップアップをスクロースして「データ保存モード」を「Excelスプレッドシート」に変更します。
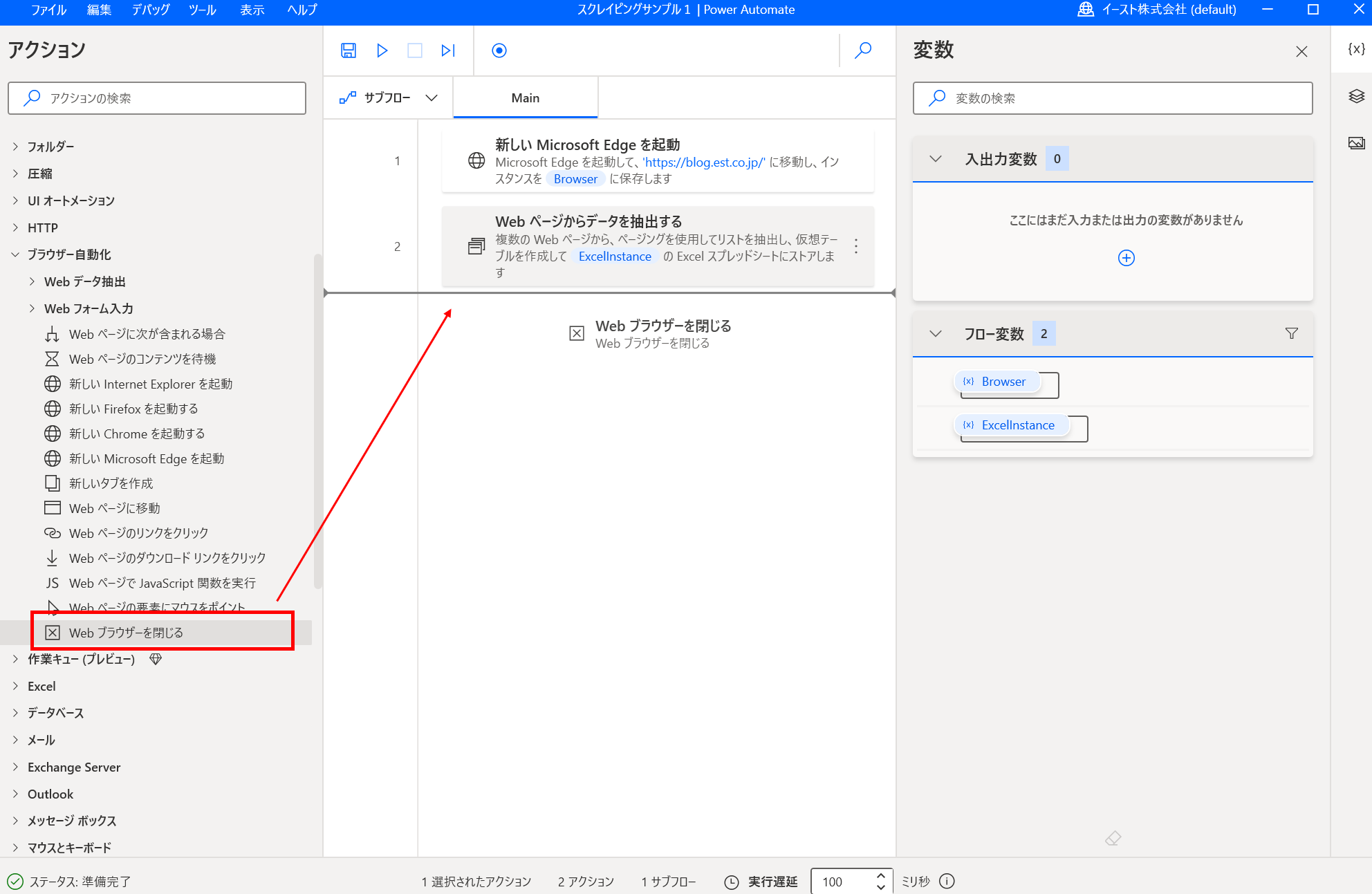
- 「Webブラウザーを閉じる」アクションを追加する 「Webブラウザーを閉じる」をドラッグアンドドロップしてフローに追加します。
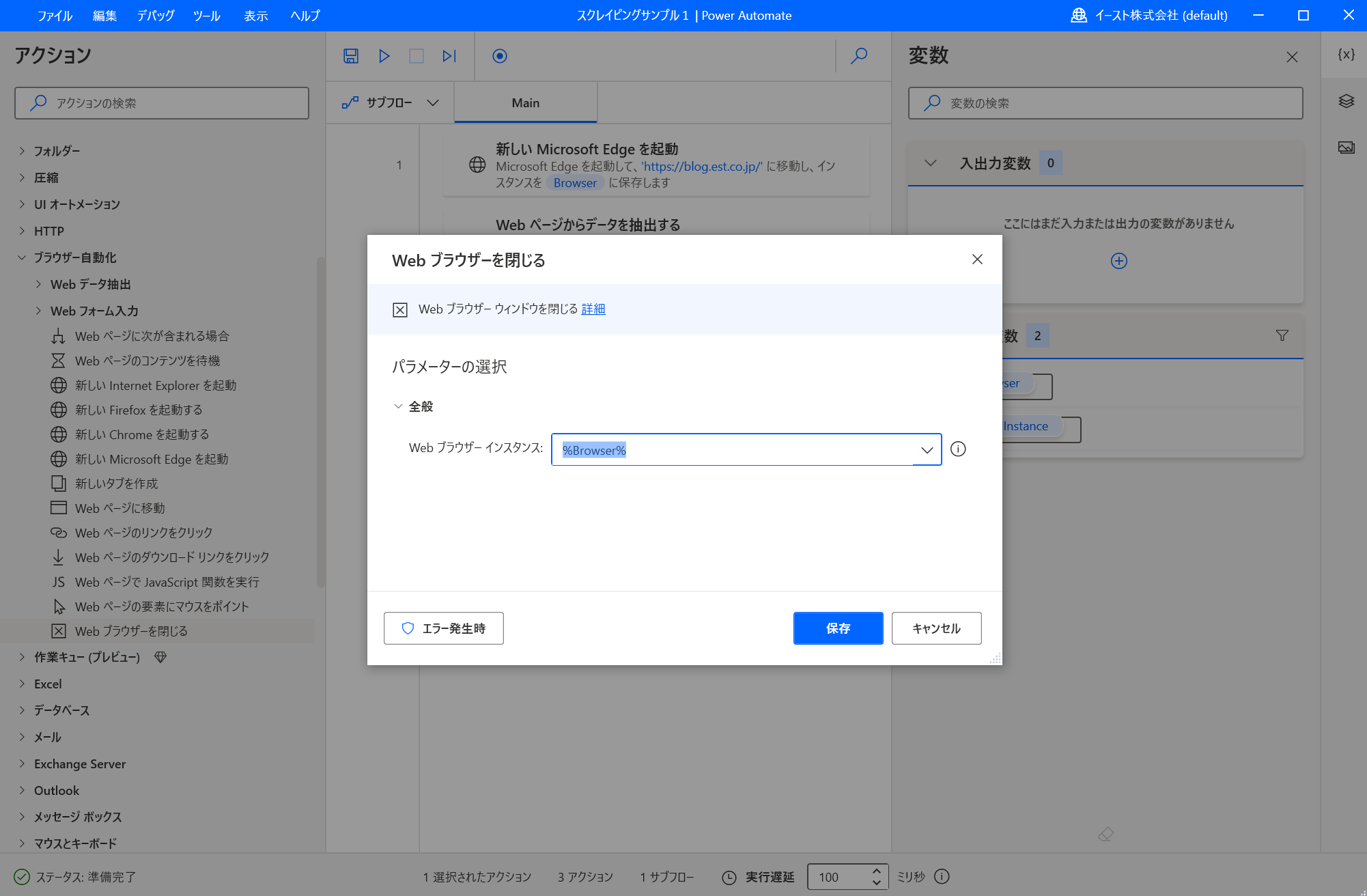
パラメーターはデフォルト値のままで「保存」をクリックします。
以上でフローの作成は完了です!
フローを実行する
作成したフローを実行してみます。 再生ボタン、またはF5キーで実行できます。
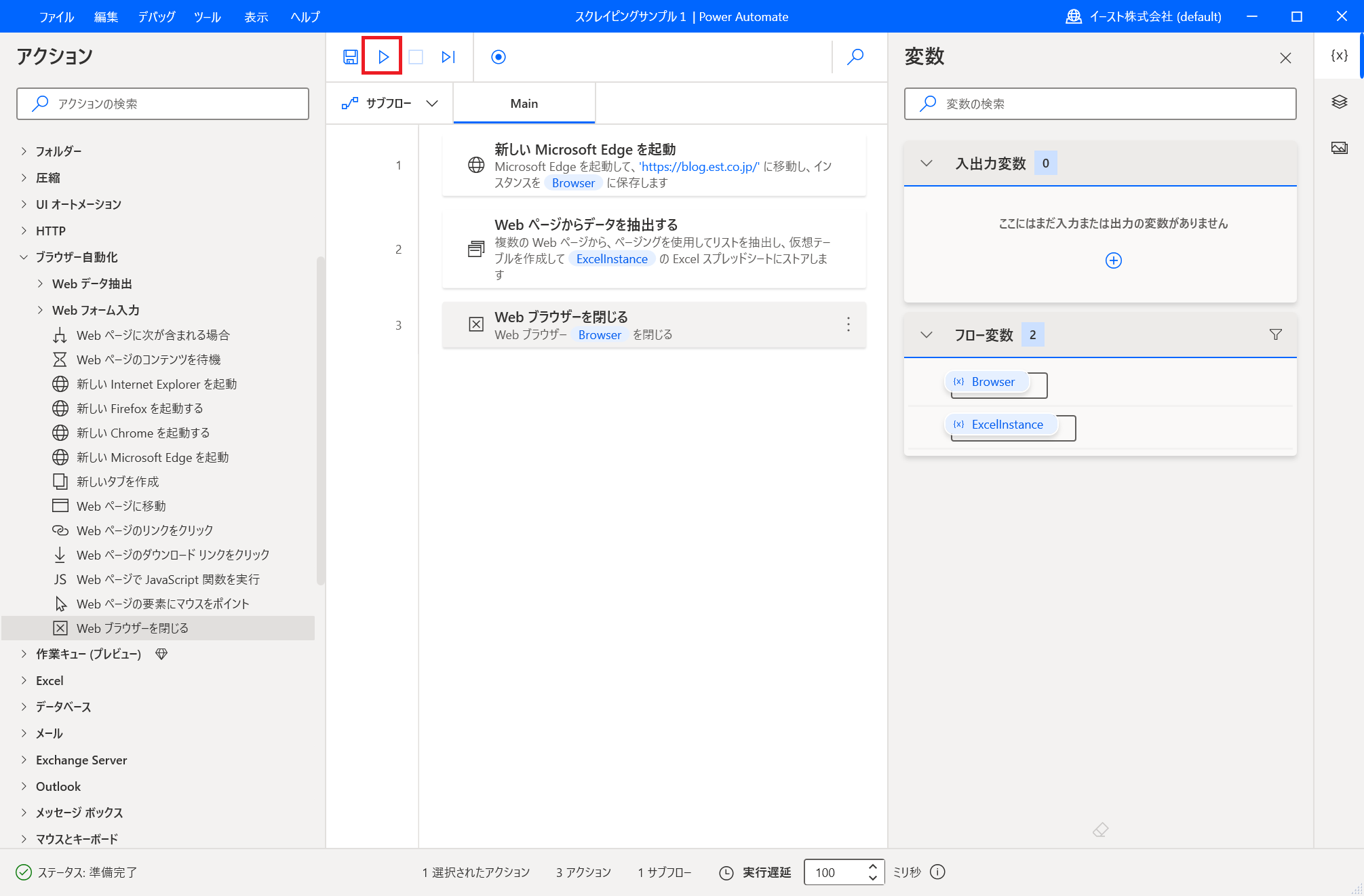
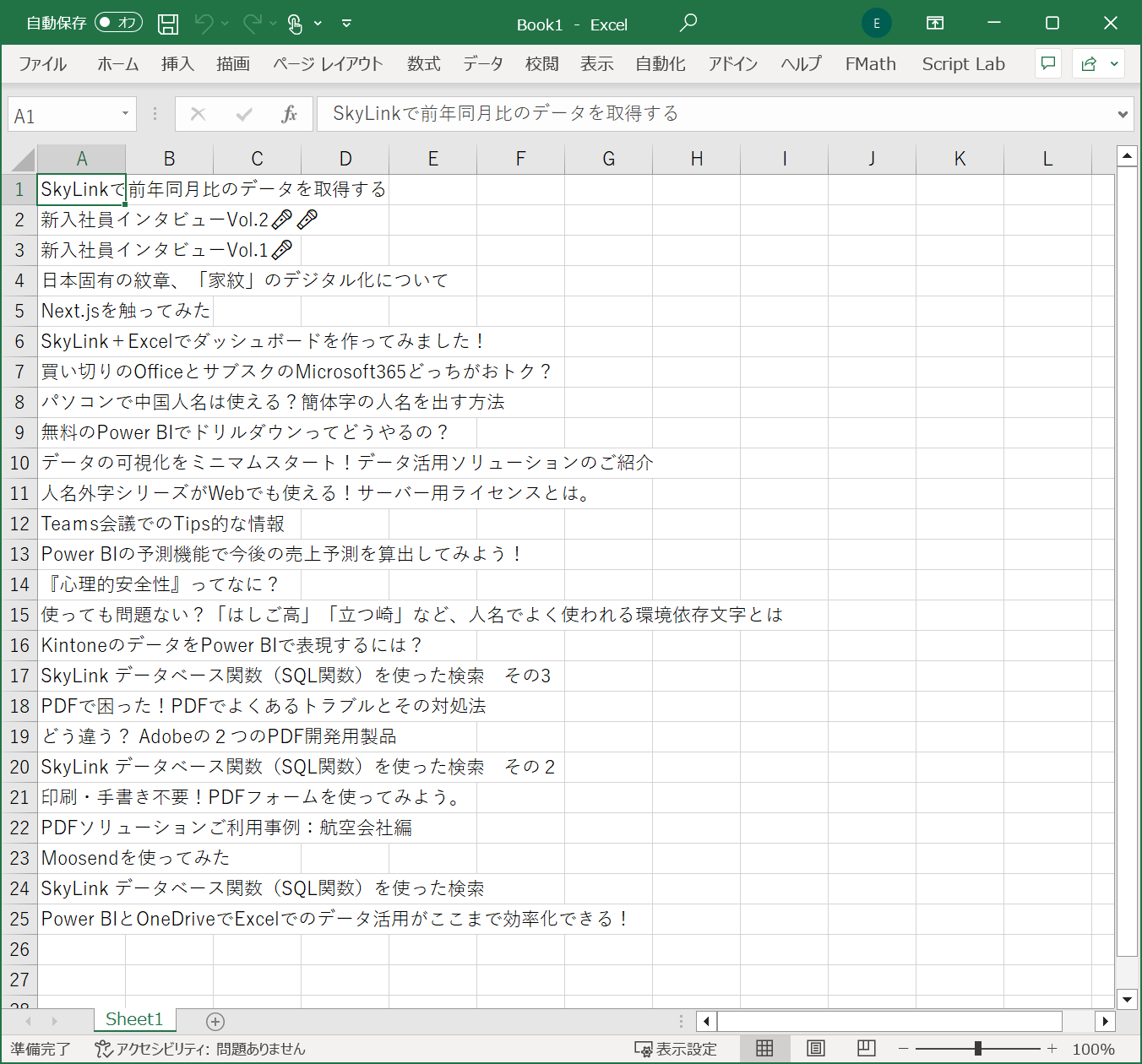
ブラウザーが起動してスクレイピングが行われた後に、 Excelが起動して記事タイトルが出力されれば成功です!
お問い合わせはコチラ
