



InformationExtractionサンプルを使ってみよう
Adobe PDF Libraryには、開発環境毎に様々な機能のサンプルコードが提供されています。今回はその中の一つ、.NET用サンプルに含まれる。InformationExtractionをご紹介します。
InformationExtractionは、PDFに含まれる各種情報を抽出して一覧表示するためのサンプルプログラムです。ブックマーク、レイヤー、クリッピングパス、メタデータ等の情報を取得することができます。
InformationExtraction サンプルの一覧
ListBookmarks
PDF ドキュメントにあるブックマークを列挙します。
このサンプルでは、PDF ドキュメントに含まれるブックマークを検索して記述します。
ListInfo
PDF ドキュメントにあるドキュメント情報メタデータを一覧表示します。
このサンプルでは、PDF ドキュメントに関するメタデータを一覧表示する方法を示し、タイトルや作成者などの値を変更する場合はコマンド プロンプトを表示します。結果は PDF 出力ドキュメントにエクスポートされます。
ListLayers
PDF ドキュメントにあるレイヤー (オプション コンテンツ) を一覧表示します。
このサンプルでは、PDF ドキュメントにある、カラーレイヤーの名前を検索して一覧表示します。
ListPaths
PDF ドキュメントにあるパスを一覧表示します。
このサンプルでは、既存の PDF ドキュメントにあるパスの内容を検索して一覧表示します。PDF ドキュメント内のパス、つまりクリッピングパスは、アートやグラフィックスの境界を定義します。
Metadata
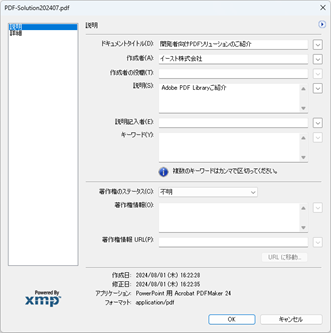
このサンプルでは、PDF ドキュメントのXMPメタデータを表示および編集する方法を示します。XMP(Extensible Metadata Platform)は、Adobe社の作成した、PDFや画像ファイルに付けることのできるXMLベースのメタデータ規格の一つで、ISOにて標準化され広く使われています。
メタデータ値は 、AcrobatなどのPDF ビューアーの [プロパティ] ウィンドウに表示されます。XMPは、[ファイル]メニューから[プロパティ] をクリックし、更に[その他のメタデータ] をクリックすると確認することができます。
まとめ

以上、InformationExtractionサンプルのご紹介でした。様々なPDFソリューションを実現する際に使える処理かと思います。
例えば、PDFを加工や変換する処理の前に、PDF内容を事前にチェックするために使えるのではないでしょうか。また、多くのPDFのメタデータの作成者を、自動的に自社名に揃えたりする自動処理などでも使えそうです。
なお、こちらは.NET環境のサンプルとなっており、下記よりご入手いただいてご利用が可能です。お気軽にお試しいただければ幸いです。
https://github.com/datalogics/apdfl-csharp-dotnet-samples/tree/main/InformationExtraction
イーストは、AcrobatなどAdobe製のPDFソリューション内で使われている、Adobe PDF Libraryの国内唯一の正規代理店です。PDFを活用するソリューションやツールの開発にAdobe純正の処理を組み込めます。Adobe PDF Libraryについては、イーストにお気軽にお問合せください。
