
はじめに
非構造化文書から構造化データを抽出したいというケースは、デジタル文書を扱う業務の中で広く存在すると思います。OCRや自然言語処理技術を使う手法が一般的ですが、最近ではGPTなどの大規模言語モデルを使って、より高度なデータ抽出が可能になってきています。しかし大規模言語モデルを使ってデータ抽出を行う場合、出力データの形式にばらつきがあるという課題がありました。
Open AIでは`gpt-4o-2024-08-06`というモデルから出力データの形式をJSONスキーマで定義できるようになりました。これによって、モデルの出力データを安定してプログラムで処理できるようになります。今回はこのモデルを使って、論文PDFからメタデータを抽出する方法を紹介します。
JSONスキーマとは
JSONスキーマ(JSON Schema)とは、JSONデータの構造や形式を定義するための標準的な方法です。具体的には、JSONスキーマを使用することで、いかのようなことが可能になります。
- データの構造の定義:JSONデータがどのような構造を持つべきか、例えばオブジェクトの中にどのようなキーが含まれているべきか、各キーの値がどのような型(文字列、数値、配列、オブジェクトなど)であるべきかを定義します。
- データのバリデーション:JSONスキーマに基づいて、あるJSONデータがその構造や形式に従っているかどうかを検証(バリデーション)できます。これにより、誤ったデータが処理されるのを防ぐことができます。
- データのドキュメンテーション:JSONスキーマを使用すると、JSONデータの仕様書としても機能し、開発者間でのデータ形式の理解を助けます。
出力データ形式
はじめに出力データ形式を定義する必要があります。論文にはJATS XML(Journal Article Tag Suite)という標準規格がありますので、これを参考にしてみましょう。今回はメタデータのみを抽出対象にしますが、JATS XMLでは `front` タグの中に記述されています。JATSではとても複雑なメタデータを記述することが可能ですが、ここでは簡潔なものを考えてみます。
サンプルのPDFファイルは、JATSのサイトに例として掲載されているものを使います。https://jats.nlm.nih.gov/publishing/tag-library/1.0/FullArticleSamples/bmj_sample.pdf

```xml
<article>
<front>
<journal-meta>
<journal-id>ジャーナルの識別子</journal-id>
<journal-title>ジャーナルのタイトル</journal-title>
<issn>ISSN番号</issn>
<publisher>
<publisher-name>出版社の名前</publisher-name>
</publisher>
</journal-meta>
<article-meta>
<article-id>記事の識別子</article-id>
<title-group>
<article-title>記事のタイトル</article-title>
</title-group>
<contrib-group>
<contrib contrib-type="著者の役割">
<name>
<surname>姓</surname>
<given-names>名</given-names>
</name>
</contrib>
</contrib-group>
<pub-date>
<year>公開年</year>
<month>公開月</month>
<day>公開日</day>
</pub-date>
</article-meta>
</front>
...
</article>
```このXMLと近い構成を持つJSON形式を考えてみます。
```json
{
"article": {
"front": {
"journal-meta": {
"journal-id": "ジャーナルの識別子",
"journal-title": "ジャーナルのタイトル",
"issn": "ISSN番号",
"publisher": {
"publisher-name": "出版社の名前"
}
},
"article-meta": {
"article-id": "記事の識別子",
"title-group": {
"article-title": "記事のタイトル"
},
"contrib-group": [
{
"contrib-type": "著者の役割",
"name": {
"surname": "姓",
"given-names": "名"
}
}
],
"pub-date": {
"year": "公開年",
"month": "公開月",
"day": "公開日"
}
}
}
}
}
```次に、このJSON形式をJSONスキーマで定義します。Open AIのGPT-4oでは、JSONスキーマを`schema` キーの中に記述します。
```json
{
"name": "paperMetadataSchema",
"strict": false,
"schema": {
"type": "object",
"properties": {
"article": {
"type": "object",
"properties": {
"front": {
"type": "object",
"properties": {
"journal-meta": {
"type": "object",
"properties": {
"journal-id": {
"type": "string",
"description": "ジャーナルの識別子"
},
"journal-title": {
"type": "string",
"description": "ジャーナルのタイトル"
},
"issn": {
"type": "string",
"description": "ISSN番号"
},
"publisher": {
"type": "object",
"properties": {
"publisher-name": {
"type": "string",
"description": "出版社の名前"
}
},
"required": [
"publisher-name"
]
}
},
"required": [
"journal-id",
"journal-title",
"issn",
"publisher"
]
},
"article-meta": {
"type": "object",
"properties": {
"article-id": {
"type": "string",
"description": "記事の識別子"
},
"title-group": {
"type": "object",
"properties": {
"article-title": {
"type": "string",
"description": "記事のタイトル"
}
},
"required": [
"article-title"
]
},
"contrib-group": {
"type": "array",
"items": {
"type": "object",
"properties": {
"contrib-type": {
"type": "string",
"description": "著者の役割"
},
"name": {
"type": "object",
"properties": {
"surname": {
"type": "string",
"description": "姓"
},
"given-names": {
"type": "string",
"description": "名"
}
},
"required": [
"surname",
"given-names"
]
}
},
"required": [
"contrib-type",
"name"
]
}
},
"pub-date": {
"type": "object",
"properties": {
"year": {
"type": "string",
"description": "公開年"
},
"month": {
"type": "string",
"description": "公開月"
},
"day": {
"type": "string",
"description": "公開日"
}
},
"required": [
"year",
"month",
"day"
]
}
},
"required": [
"article-id",
"title-group",
"contrib-group",
"pub-date"
]
}
},
"required": [
"journal-meta",
"article-meta"
]
}
},
"required": [
"front"
]
}
},
"required": [
"article"
]
}
}
```実践
それでは、実際にGPT-4oを使ってPDFからメタデータを抽出してみましょう。Open AIでは様々なプログラム言語のSDKが提供されていますが、ここでは簡単に試せるように、Playground のGUIを使ってみます。
`gpt-4o-2024-08-06` モデルのPlaygroundは以下のリンクからアクセスできます。
https://platform.openai.com/playground/chat?models=gpt-4o-2024-08-06
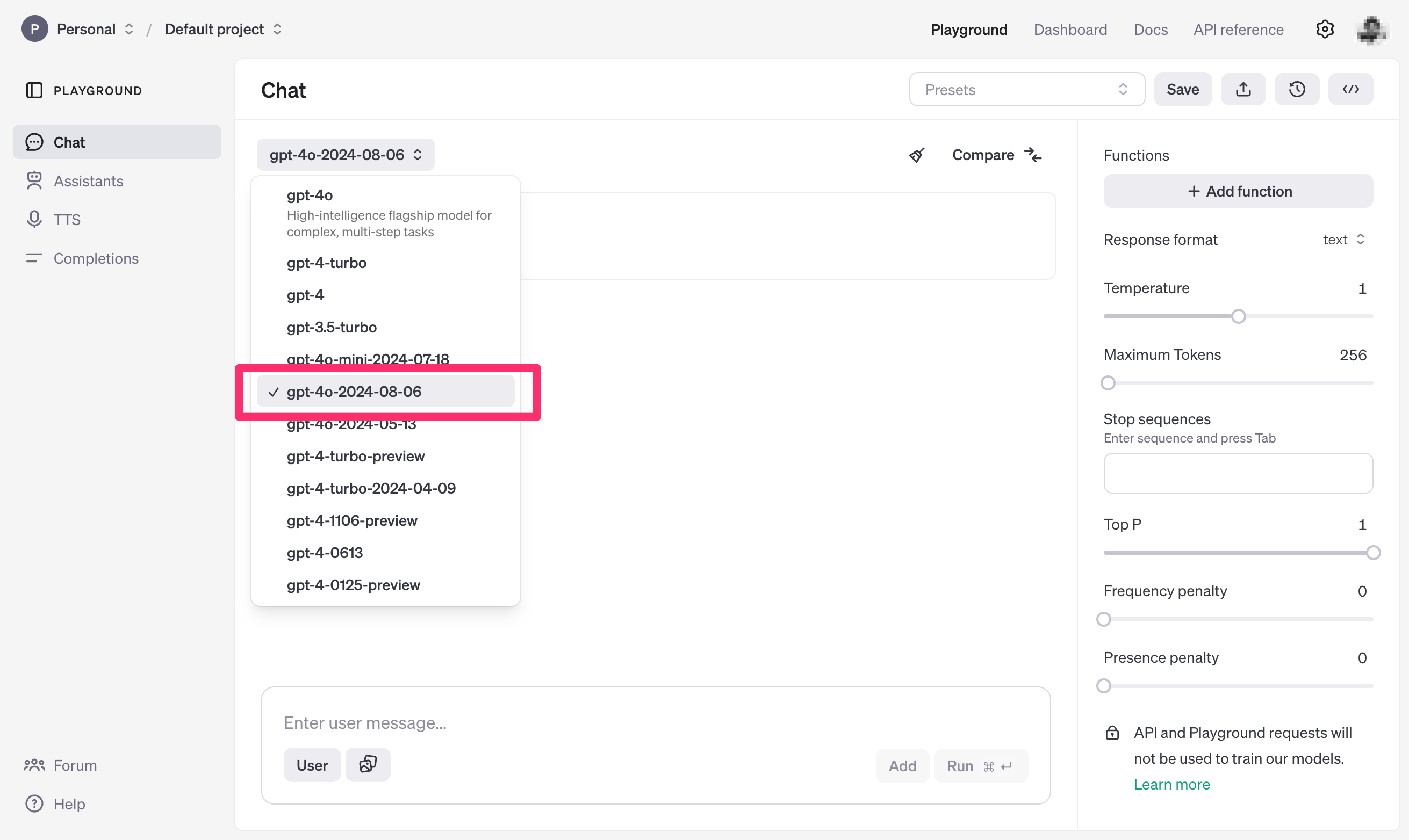
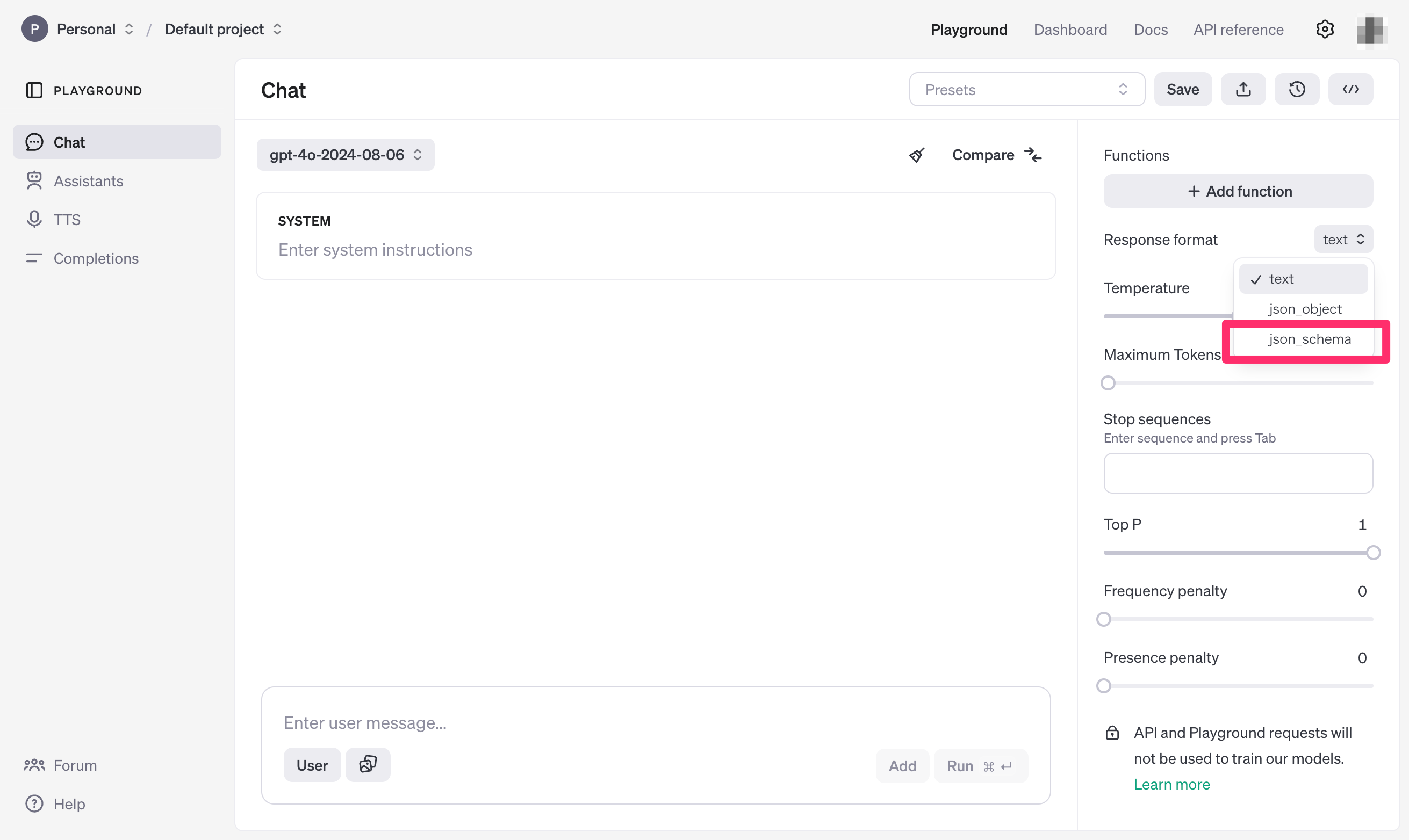
モデルを指定せずにPlaygroundを開いた場合は、gpt-4oモデルがデフォルトで選択されているので、プルダウンから `gpt-4o-2024-08-06` に切り替える必要があります。 また、JSONスキーマでレスポンス形式を定義するため、右ペインの `Response format`で `json_schema` を選択します。すると Add response format というポップアップが表示されるので、ここに先ほど定義したJSONスキーマを貼り付けます。

Playground ではPDFをアップロードできないので、先頭のページを画像に変換してアップロードします。 プロンプトはシンプルに `Extract metadata from the image` としてみます。
結果
以下のような結果が得られました。他の論文でも同様の形式でメタデータを抽出できか確認しながら、
プロンプトを改良していくことで、より高度なデータ抽出が可能になります。
```json
{
"article": {
"front": {
"journal-meta": {
"journal-id": "bmj",
"journal-title": "BMJ",
"issn": "0959-8138",
"publisher": {
"publisher-name": "BMJ Publishing Group"
}
},
"article-meta": {
"article-id": "3247342880",
"title-group": {
"article-title": "Evolving general practice consultation in Britain: issues of length and context"
},
"contrib-group": [
{
"contrib-type": "author",
"name": {
"surname": "Freeman",
"given-names": "George K"
}
},
{
"contrib-type": "author",
"name": {
"surname": "Horder",
"given-names": "John P"
}
},
{
"contrib-type": "author",
"name": {
"surname": "Howie",
"given-names": "John G R"
}
},
{
"contrib-type": "author",
"name": {
"surname": "Hungin",
"given-names": "A Pali"
}
},
{
"contrib-type": "author",
"name": {
"surname": "Hill",
"given-names": "Alison P"
}
},
{
"contrib-type": "author",
"name": {
"surname": "Shah",
"given-names": "Nayan C"
}
},
{
"contrib-type": "author",
"name": {
"surname": "Wilson",
"given-names": "Andrew"
}
}
],
"pub-date": {
"year": "2002",
"month": "04",
"day": "13"
}
}
}
}
}
```
