



こんにちは!事業推進チームです。
Power BI を使っていて、
「データ量が増えるとレポートが重くなる」
「スライサーを操作すると反応が遅い」
と感じたことはありませんか?
実はその原因、Excelのデータ構造 にある場合があります。
※ Power BIの「動作が重い」「データ設計が不安」といった課題は、データモデル設計を見直すだけで大きく改善するケースが多くあります。
イーストでは、Power BI導入・初期設計の段階から支援しています。
▶ Power BI導入支援サービスの詳細はこちら
https://promo.est.co.jp/lp/skylink-data-utilization
今回は、Excelに1枚でまとまったデータをスター型(またはスノーフレーク型)に分解してPower BI のパフォーマンスを改善する方法をご紹介します。
■ Excelデータの状態
まず、よくあるExcelデータを見てみましょう。

列には、[受注コード][得意先名][得意先担当者名][得意先部署][得意先所在地][区分名][商品名][受注日][金額][担当部署][担当社員]が含まれています。
一見すると問題なさそうに見える、所謂「全部入りテーブル」です。
もちろん、そのままPower BIに取り込んで利用することができますが、データの量が膨大になった場合などでは、次のようなことが考えられます。
■ Excel1枚構成の問題点
次のような問題のため、表示が遅くなる可能性があります。
- 顧客名・商品名・社員名が 何度も繰り返し出てくる
- データ量が増えるほど モデルが重くなる
- リレーションが貼れず、DAXが複雑になりがち
- Power BI の 圧縮効率が悪い
■ スター型(スタースキーマ)とは?
このような場合、スター型のスキーマにすることで解消されやすくなります。
それでは、スター型とはどういったものでしょうか。
- 売上などの数値を持つ「売上テーブル」
- 分析の切り口となる マスタテーブル(顧客・商品・社員など)
これらを分離してリレーションシップで関連付けをおこなうものです。
表示対象となる「売上テーブル」を中心として星(スター)のような構造 にする設計方法です。
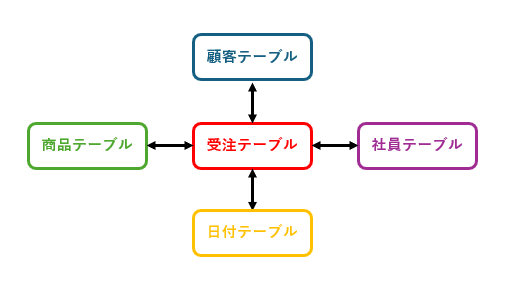
■ 今回作成するテーブル構成
Excel1枚のデータを、以下の4つに分解します。
① 売上テーブル(Fact) 受注日/受注コード/得意先ID/商品ID/社員ID/売上金額
② 得意先テーブル(Dimension) 得意先ID/得意先名/所在地 など
③ 商品テーブル(Dimension) 商品ID/商品名/区分名 など
④ 社員テーブル(Dimension) 社員ID/社員名/部署名 など
■ 得られるメリット
✅ パフォーマンスが向上
Power BI は、「ID列(数値)+リレーション」 の構造が最も高速となります。
文字列の重複を排除することで、
- モデルサイズが小さくなります
- 集計処理が速くなります
✅ レポート設計がシンプル
- スライサーは得意先・商品・社員テーブルを配置
- 売上金額は売上テーブルから参照
「どこに何があるか」が明確になります。
■ Power BIでの作成手順(Power Query)
ここからは、Excel に1枚でまとまったデータを、売上・得意先・商品・社員の各テーブルに分割する手順をご紹介します。
Power BI DesktopのPower Queryを使えば、GUI操作だけで簡単に作成できます。
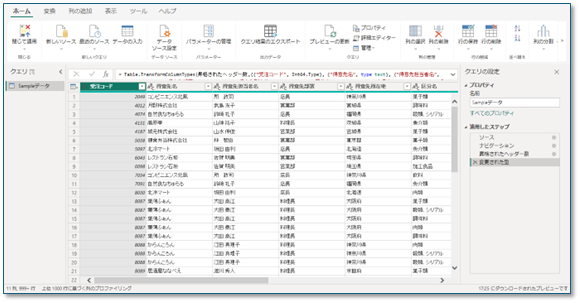
① 元Excelデータの読み込み
- Power BI Desktopを起動
- [データの取得]→[Excel]を選択
- 元データのExcelファイルを指定
- 対象のシートを選択し、[データの変換]をクリック
ここでは、Excel1枚にすべての情報が入っている状態を想定しています。
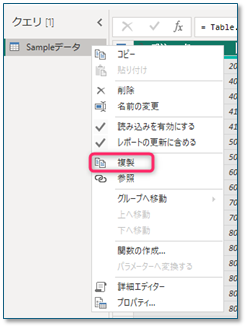
② 得意先テーブルを作成
- 元データのクエリを 右クリック →[複製]
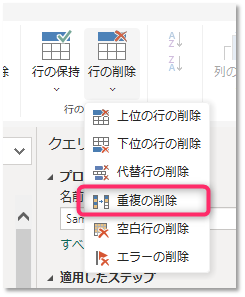
- 以下の列だけを残します
- 得意先名
- 得意先担当者名
- 得意先部署
- 得意先所在地
- [重複の削除] を実行
- [インデックス列]を追加
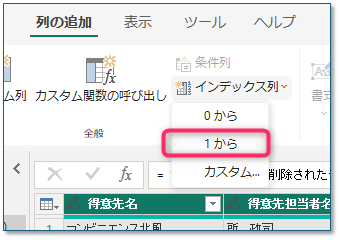
- クエリ名を「得意先テーブル」に変更
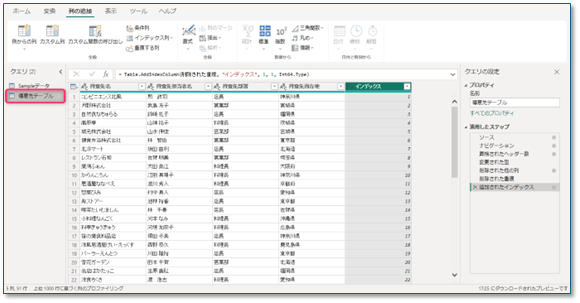
👉 これで顧客マスタが完成です。
同様の手順で[商品テーブル][社員テーブル]も作成します。
③ 追加したテーブルを元のテーブルにマージします
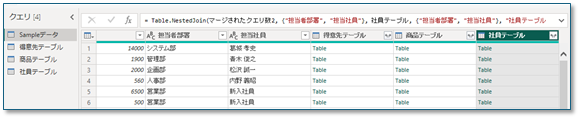
④ マージしたテーブルのインデックスを列として使用
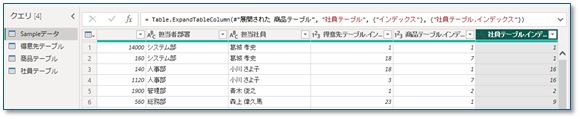
⑤ 元テーブルの名前を[売上テーブル]に変更して複製した列は削除
最後に、売上(Fact)テーブルを整えます。
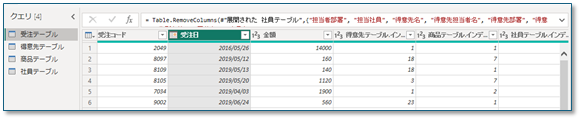
👉 数値と日付、IDだけを持つ、シンプルな構造にします。
⑥ リレーションシップを設定する
- クエリを適用
- [モデルビュー] に切り替え
- 以下のリレーションを設定
- 売上テーブル(多) → 得意先テーブル(1)
- 売上テーブル(多) → 商品テーブル(1)
- 売上テーブル(多) → 社員テーブル(1)
設定のポイント:
- 1対多
- 単方向(マスタ → 売上)
- クロスフィルターは「単一」
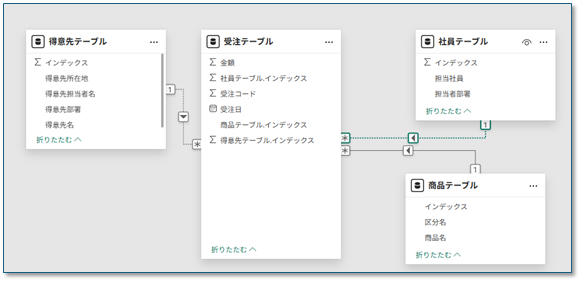
⑦ スター型モデルの完成
これで、Power BI が最も得意とするスター型(スタースキーマ)モデル が完成します。
ここまでの手順は、Power Queryに慣れていれば比較的スムーズですが、
- データ量が多い
- マスタが複雑
- 既存レポートがすでに動いている
といったケースでは、設計を誤ると「作り直し」「想定外のパフォーマンス低下」につながることも少なくありません。
イーストでは、Power BIのデータモデル設計(スター型・スノーフレーク型)から、既存レポートのパフォーマンス改善まで支援しています。
▶ Power BI導入・活用支援サービスを見る
https://promo.est.co.jp/lp/skylink-data-utilization
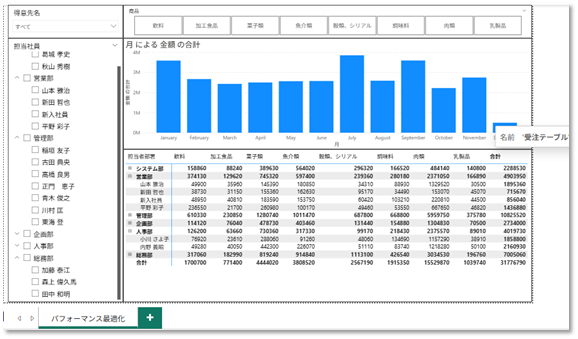
この構造にすることで、
- データモデルが軽くなる
- 集計・スライサー操作が高速になる
- DAX が書きやすくなる
といった効果が得られます。
■ スノーフレーク型になるケース
もし商品カテゴリや部署マスタをさらに分けたい場合は、
- 商品 → カテゴリ - 社員 → 部署 のようにスノーフレーク型になります。
ただし、基本はスター型、必要なところだけ分割がおすすめです。
■ まとめ
Excel1枚のデータでも Power BI は使えますが、データモデルをスター型にするだけで
- レポートが軽くなる
- 設計が分かりやすくなる
- 将来の拡張に強くなる
という大きなメリットがあります。
一方で、
「どこまで分割すべきか」
「既存レポートにどう影響するか」
「今後の運用も見据えた設計」
まで考えるのは、意外と難しいものです。
イーストでは、Microsoft認定データアナリストがPower BIの導入・設計・内製化支援まで一貫してサポートしています。
👉 パフォーマンスに悩んでいる
👉 これからPower BIを本格導入したい
👉 Excel運用から脱却したい
そんな方は、ぜひ一度ご相談ください。
【Power BI導入支援サービスの詳細はこちら】
https://promo.est.co.jp/lp/skylink-data-utilization
